SFMC SQL Inner Join – Overview
The SFMC SQL Inner Join function merges two or more Data Extensions including the records that are shared across the two (or more) data extensions being joined.
In other words, it retrieves records that are found both in table A and table B thanks to a shared field.
Here is a diagram where you can see how it works visually:
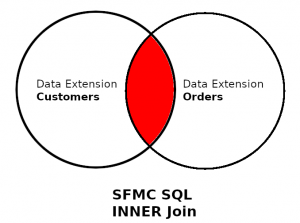
Data Extension A is Customers.
Data Extension B is Orders.
If you perform an INNER JOIN with both tables, saying that these two tables shared a common field, the records from Customers that you will get must be found in the table Orders as well.
Therefore, those Customers must be Customers who placed an order.
This function also allows you to retrieve fields from any of the joined Data Extensions, which can be super useful in SFMC.
Inner Join – Basic Syntax
This is the basic syntax of an SQL Inner Join function:
SELECT a.Field FROM [Data Extension A] a INNER JOIN [Data Extension B] b ON a.Field1 = b.Field1
Joins in SQL always come right after the FROM statement. The FROM in this example is written with Data Extension A:
FROM [Data Extension A] a
Then, type INNER JOIN and the name of the second Data Extension from which you’ll be getting the cross-shared records.
INNER JOIN [Data Extension B] b
Finally, use ON at the next line of code to say what common field in both tables we will use to check this record-sharing relationship.
Type what field in Data Extension A corresponds to what field in Data Extension B, like this:
ON a.Field1 = b.Field1
As you will have noticed, we need to use an ALIAS when joining tables with the SQL Inner Join function.
An ALIAS is just a short letter or phrase (e.g: t, tmp, s, d, o) that you use to name each Data Extension in the join, written after the name of the Data Extension in the SQL statement. For example:
FROM [Data Extension A] a
I could give the ALIAS “a” to Data Extension A, as an example.
The use of an ALIAS allows you to define what field corresponds to what Data Extension, so your SELECT statement doesn’t confuse the fields. For instance:
SELECT a.Field1
This means –> Give me the column with name “Field1” from Data Extension A, with ALIAS “a”.
In the following SELECT, I am retrieving columns from both Data Extension A and B, each with a different column name:
SELECT a.OrderID, a.OrderQuantity, b.CustomerID, b.CustomerPhone
Notice how the use of an ALIAS is also required in the ON line, where you define what column in the first Data Extension corresponds to what column in the second Data Extension.
ON a.Field1 = b.Field1
Your SFMC SQL Queries will throw an error if the name of a Data Extension has spaces and you do not type it between square brackets []. To prevent errors, always write DE names within them.
[Data Extension Name With Spaces]
Inner Join – Shared Keys & Matching values
Single Shared Key
One of the core elements of any JOIN SQL function is the shared column(s) between the tables that you’re joining.
This is usually called a shared key or matching column.
Basically, it is what tells the SQL function that the values in Table A have matching values in Table B, as that shared column (key) is found in both tables.
In an SQL Inner Join function, we represent this like the following, using ON and adding the two shared columns:
SELECT a.CustomerID b.Order FROM [Customers] a INNER JOIN [Orders] b ON a.CustomerID = b.CustomerID
This means, the key CustomerID is found both in the table Customers and in table Orders. So, if John has CustomerID = 001, then we will get all the orders where in table Orders, the CustomerID column has value = 001.
Multiple Shared Keys
You might want to make a JOIN based on multiple keys, not only one column.
This is especially relevant when you need accuracy (the matching records have multiple key columns as Primary Key, not only one).
If you wanted to retrieve Orders from Customers based on not only the OrderID but also the Brand of each order, you could add an extra shared key in the JOIN, like this:
FROM [Customers] a INNER JOIN [Orders] b ON a.CustomerID = b.CustomerID AND a.CustomerBrand = b.CustomerBrand
Join based on a subquery or dataset
You can also make a more advanced JOIN with a Subquery. This is, instead of joining based on a common column (or key) between two tables, you join based on a specific dataset, using a Subquery.
Why?
Perhaps joining based on a common key is not enough to identify the dataset you want to use as criteria for the join. Let’s consider the following:
You want to join Customers based on the nº of orders they have placed, with minimum 5 orders. The nº of orders placed is not identifiable from a key column (no column tells you this information, it has to be worked out with a formula or further SQL functions).
In this case, we would use a subquery calculating those Customers from Orders who have placed at least 5 orders, and then we would join based on this subquery.
- Calculate the specific dataset you want to join on (Orders where the Customer has placed at least 5 orders):
SELECT o.CustomerID, o.OrderID FROM [Orders] o GROUP BY o.OrderID HAVING COUNT(orderID) > 5
That’s our first SQL Query. A dataset of all the orders (OrderID and the corresponding CustomerID) where the customer placed at least 5 orders.
- Now, we perform our INNER JOIN not based on a common column, but on this subquery:
SELECT c.CustomerID FROM Customers c INNER JOIN ( SELECT o.CustomerID, o.OrderID FROM [Orders] o GROUP BY o.OrderID HAVING COUNT(orderID) > 5 ) AS OrderCounts ON c.CustomerID = OrderCounts.CustomerID
Notice how the use of an ALIAS is required when you create a Subquery. Otherwise, when we write the ON line afterwards, we would not know how to select the fields in which we base our matching values.
ON c.CustomerID = OrderCounts.CustomerID
You might be wondering whether using a Subquery in a JOIN is the same as performing a simple JOIN with the shared keys and then, applying WHERE conditions to calculate the same dataset (e.g: customers who placed at least 5 orders).
Not exactly the same in terms of performance. Making a full join will first retrieve ALL the dataset and only then, will it apply the WHERE conditions to “slice” that large dataset. By using the conditions directly in the Joined Subquery, you obtain faster results.
Inner Join – Use Cases & Examples
This SQL Function is really useful in SFMC development and data segmentation. Below are some of the most common use cases:
SQL Inner Join for Data Retrieval
When you need to combine segmentation data from more than one table, then an Inner Join is the perfect solution. For example:
- Customers (DE 1) who registered a voucher code (DE 2)
- Customers (DE 1) who placed an order (DE 2)
- Catalogue Products (DE 3) which exist in a specific local market (DE 4)
Customers who registered a voucher code
SELECT a.CustomerID,
a.CustomerName,
a.CustomerEmailAddress,
b.VoucherID,
b.VoucherQuantity
FROM [Customers] a
INNER JOIN [Vouchers] b
ON a.CustomerID = b.CustomerID
Customers who placed an order
SELECT a.CustomerID,
a.CustomerName,
a.CustomerEmailAddress,
b.OrderID,
b.OrderQuantity
FROM [Customers] a
INNER JOIN [Orders] b
ON a.CustomerID = b.CustomerID
SQL Inner Join for Data Enrichment
Using an Inner Join can enrich your data by allowing you to select additional fields from a second (or third) Data Extension.
For example, say that you’re retrieving data from the Customers table to prepare an email campaign.
You’re using some personalization with customers’ First Name, Email Address and Address. However, you also want customers to be reminded of their Voucher Code information (which is found in a second Data Extension).
You can use an Inner Join to get the fields from the Vouchers table:
SELECT a.FirstName,
a.EmailAddress,
a.Address,
b.VoucherCode,
b.VoucherExpiration
FROM [Customers] a
INNER JOIN [Vouchers] b
ON a.CustomerID = b.CustomerID
SQL Inner Join for SFMC Data Views & Reporting
The SFMC SQL Inner Join function is very useful when you need to generate reporting data that cross-checks information from SFMC _Data Views.
For instance, say that you are getting data from the _Sent Data View (to get info about all the customers who received an email campaign).
However, you also need to cross-check with the _Job Data View to get the fields EmailName, FromName and the SendClassification for each send, so that your report looks more detailed.
You would use an SQL Inner Join with both data views, like this:
SELECT s.JobID,
s.ListID,
s.SubscriberKey,
s.EventDate,
j.FromName,
j.EmailName,
j.SendClassification
FROM _Sent s
INNER JOIN _Job j
ON s.JobID = j.JobID
Please note how we do not use square brackets [ ] for Data Views names, as they are just one word (no spaces). Also, I used the ALIAS s for _Sent and j for _Job, for the sake of clarity. This comes in handy when you’re writing more advanced and longer queries with multiple joins.
Inner Join – Best Practices
SQL Performance Issues
Salesforce Marketing Cloud has a 30-minute timeout limit for SQL Queries.
This, when Data Extensions have large record volumes, can be an issue if you are using a lot of Inner Joins. Why?
Think of how SQL works when using an Inner Join. The processing order of the algorithm is something like the following:
- Parsing the syntax of the query
- Table or Index Scans of each table
- Matching rows comparison
- Combining matching rows
- Filtering non-matching rows
- Creating result set.
Now imagine all those processing steps if each Data Extension in your Inner Join has 50 million rows, and you have 3 inner joins in the same SQL Query.
Using Sub-Queries results in better performance than with multiple inner joins. If possible, you can try to use a Sub-Select and then segmentate the only relevant rows for the matching rows comparison.
Example:
SELECT SubscriberKey
FROM _Sent
WHERE SubscriberKey IN(
SELECT SubscriberKey
FROM _Click
WHERE ....
)
How to improve performance of your inner joins
When possible, try to segment your data and filtering criteria as much as possible.
Some useful ways to improve performance:
- Limit Result size by only selecting the relevant columns that you need.
- Avoid creating Inner Joins with large Data Extensions.
- Using an INT(Number data type) is faster than a VARCHAR(text data type) column for your joins.
- Segment as much as possible so that you’re only getting a very specific subset of your data.
- Try to use a Sub-Query with a sub-select whenever you can.
- Normalize your Data Model and Data Extensions as much as you can so that you avoid redundancy.
Further Reading
For further understanding of SFMC SQL Inner Joins, check out the following resources: